Good news, I have plenty of flash memory still available.
Bad news, it begins to look like RAM could be a challenge.
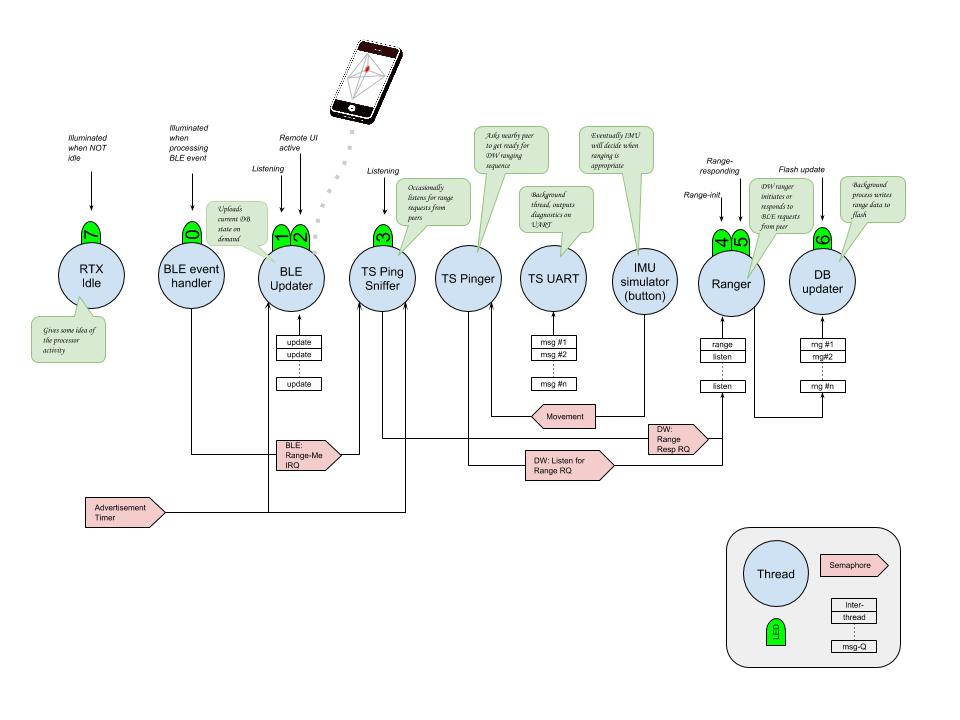
My proposed architecture (see below) uses 10 threads (1 main thread, and 9 others). This architecture is clean and easy to understand. At present I have 5 threads part implemented. Each thread demands a different amount of stack, which obviously has to be in RAM. The amount depends on how deeply the procedure calls are nested. I have tuned the current stack definitions down to the bare minimum required for them to run without overflowing.
By default, each stack requires 256 x 32-bit words – i.e. 1Kb. I have tuned two of the stacks down to 768 bytes. Assuming that I need another 6 threads then thats another 6K. The current splash screen shows that there is only 1.3K left!
—- Touchstone Labs —-
RAM: 32K (Avail: 22K / bss free: 1.3K)
FLASH: 256K (Used: 119K)
SW: BLE_RTX_UART(Feb 12 2016 01:40:04)
HW: ts06.3
RTOS: RTX V4.74 + SoftMach: s130
API: DW1000 Device Driver Version 03.00.01
SPI0 0: ss:7, mo:6, mi:5, sck:4, Hz:125K, BLOCKING
BUTTONS 0:16 1:17
UART: tx:14, rx:15, cts:255, rtx:255, hwfc:false
SPLR Thread: 0x20005c90
DECA: RSTN 25, EXTON 29, WAKEUP 28, IRQ 3
AntDel TX: 16453 RX: 16453
I2C SCL 9, SDA 8
DC2DC SHDNn 20, PWRON 19, GG_ALARM 18
BARO INT 13
IMU INT 12
uSD CDn 11, CS 10
BLE Thread: 0x20005cc4 — handles all BLE events from soft-machine
ADV Thread: 0x20005cf8 — kicks off periodic advertizing cycle
CLI Thread: 0x20005d2c — responds to range commands sent over BLE
The DW libraries are not being used yet. They actually demand a lot of I/O packet space themselves. 1-2K.
So what can be done?
Runtime libraries
A lot of the overhead goes in C runtime libraries to do text formatting and so forth. The RTX documentation recommends 1Kb/thread, which I have nevertheless trimmed down to 768 bytes. If I dispensed with all debug messages I could save some stack space. That would make debugging more of a pain though.
Combine threads
Combining threads into one unified handler is the easiest way to save space, but it also makes the architecture a lot less elegant, harder to understand, and debug One approach is to combine all the non-BLE threads into one large hairy thread that can process all types of event. Unfortunately the BLE events have to be handled by a high priority thread in order to meet the response requirements. So BLE handling needs it’s own thread
Combining threads would require that there is a common message format for passing messages from each kind of interrupt handler to the unified event handler routine that does the actual processing work. That in turn means that every message has to carry the overhead of the largest message – but not sure this is a big issue.
Make the main loop more useful
The diagnostic (TS UART) thread could perhaps be moved into the main idle loop, and maybe persuaded to run at a lower priority.
Don’t write data to flash
My plan was to write all activity data to flash memory (or flash card) so that when the device moves back into range of a cloud connection it can upload all the activity data it has collected while disconnected. Writing and reading flash is slow, and power intensive, so I put it in a separate thread. To be able to write the data without using flash it has to be stored in RAM. There is clearly a trade off between stack space for a separate flash-writing thread, and a simpler scheme that just uses RAM. I don’t know how much RAM I need in practice. The theoretical answer is “lots” because you don’t know how long you might be disconnected. A flash-writing thread would require 1KB, but just using a 1KB RAM buffer might hold enough activity data for a first iteration.
What’s the best we could expect?
1 Combo main thread: RTX Idle is combined with TS_UART which saves one thread.
0 Using RAM to store events, instead of flash updater
1 High priority BLE “interrupt” handler
1 Combo thread for BLE discovery/wakeup; DW activities; IMU; Flash updater
1 Timer thread
1 Timer thread
That gets us down from 10 threads to 4 threads.
So there is the possibility to save ~6K, but probably burn some in new IPC buffers
So maybe I can scavange 7KB is I sweat the details, and that might do the trick. On the other hand the nRF52 processor has more RAM, but I’d have to port the code before I could continue. It would be good to get some sort of results before rolling new hardware.